1. 서
부스트캠프 3일차 정리이다. 오늘은 도메인 별 전체 팀 소개를 하는 시간이 있었는데, 부스트캠퍼분들 중에는 INTP분들이 신기할 정도로 많이 있었다. 생각해보니 내향, 직관, 사고, 인식의 INTP는 개발자에 잘 맞을것 같다. 어쨌든 오늘까지 해서 파이썬 관련 내용 리뷰를 마치고 내일부터 AI math 부분의 내용 리뷰를 시작할 수 있도록 하는 것이 목표이다. 지금처럼 시간에 치일수록 선택과 집중이 강조된다. 그래서 오늘 새기려는 공부명언은 "모든 불의타를 준비하는 것은 모든 것을 불의타로 만든다"이다.
2. 학습내용 리뷰 - 여러가지 Handling, Numpy, Pandas
(1) 여러가지 Handling - Exception, File, Logging, Data
1) Exception Handling
- assert문
assert문은 특정 조건 충족 여부를 판단하여 거짓일 경우 예외를 발생시키는 문법이다. 일반적으로 디버깅 목적으로 사용되는데, 프로그램의 안정성 검사나 오류처리를 위한 대체방법으로는 권장되지 않는다. 즉, 디버깅 시간에만 활성화되어야 하고 운영 환경에서는 비활성화 되어야 하는데, 파이썬의 -O(optimize) 옵션을 사용하면 모든 assert문들을 비활성화 할 수 있다.
def divide(a, b):
assert b != 0, "두 번째 인자는 0이 될 수 없습니다."
return a / b
result = divide(10, 2)
print(result) # 출력: 5.0
result = divide(10, 0)
print(result) # AssertionError: 두 번째 인자는 0이 될 수 없습니다.assert문의 예시이다. 위에서 말한 비활성화를 위해서는 터미널 등에 python -O 이름.py 의 명령어를 입력해야 한다.
- try except문
try except문은 try문 실행 중 오류발생시 except문을 실행한다. 오류가 발생하지 않는경우 실행하는 else문이나 오류 발생불문 실행하는 finally문과 결합되어 사용되기도 하고, 오류가 여러개일시 여러 except문이 등장하기도 한다.
try:
num1 = int(input("첫 번째 숫자를 입력하세요: "))
num2 = int(input("두 번째 숫자를 입력하세요: "))
result = num1 / num2
print("나눗셈 결과:", result)
except ValueError:
print("유효한 숫자를 입력해주세요.")
except ZeroDivisionError:
print("0으로 나눌 수 없습니다.")예시와 같이 오류종류를 지정하여 쓸 수도 있지만, 단순히 except:로 쓰면 모든 오류에 대응하여 except문을 수행하게 된다. except문에서 pass를 통해 오류를 회피하게 할 수 도 있다.
- raise문
raise문은 예외를 강제로 발생시키는 역할을 한다.
def divide(a, b):
if b == 0:
raise ZeroDivisionError("0으로 나눌 수 없습니다.")
return a / b
2) File Handling
- 파일 열기
파이썬에서는 open함수를 통해 파일을 열 수 있다. open함수는 파일이름과 읽기/쓰기/추가모드(각각 r,w,a)를 입력받아 파일 객체를 리턴하는 함수이다. 파일을 쓰기모드(w)로 여는 경우 알아 둘 것은, 존재하지 않는 파일이면 새로운 파일이 생성되고, 존재하는 파일이면 원래 내용이 모두 사라진다는 점이다. 즉 기존 내용에 추가로 적으려면 추가모드(a)로 한다.
파일을 열때는 인코딩을 신경써야 한다. open()함수는 encoding 매개변수를 지정할 수 있는데, 미지정시 기본인코딩 방식으로 열게 된다. 보통은 UTF-8 인코딩이 기본값으로 사용된다. 윈도우에서는 CP949 방식도 많이 사용된다.
file = open('파일명.txt', 'r', encoding='utf-8')예시 코드이다. 여기서 'utf-8' 대신 'utf8'로 써도 무방하다.
- 쓰기
파일에 내용을 쓰려면 w나 a모드로 파일을 열고 write메서드를 이용해 내용을 작성하게 된다.
# 파일 열기
file = open("example.txt", "w")
# 파일에 쓰기
file.write("Hello, World!\n")
file.write("안녕하세요!\n")
# 파일 닫기
file.close()위 예시처럼 그냥 쓰면 되지만, 특정 인코딩 방식으로 쓰는 경우에는 파일을 열때 encoding을 지정해 주어야 한다. 예를들면, open("example.txt", "w", encoding="utf-8")과 같은 방식으로 쓰게 된다.
- 읽기
파일을 읽으려면 read모드로 파일을 열고 메서드를 이용해야 하는데, read(), readline(), readlines() 메서드가 있다. read() 메서드는 파일 내용 전체를 문자열로 리턴한다. readline() 메서드는 파일을 한줄씩 읽는 함수로, 각 호출마다 다음 줄을 읽어온다. readlines() 메서드는 파일의 모든 줄을 읽어 각 줄이 요소로 들어가는 리스트를 리턴하는 함수이다.
# readlines() 예시
file = open("example.txt", "r")
lines = file.readlines() # 모든 줄 읽기
for line in lines:
print(line.strip()) # 줄바꿈 문자 제거 후 출력
file.close()예시에서와 같이 파일을 open함수로 열면 close함수로 닫아주는게 좋은데, with문을 사용하면 자동으로 파일을 닫아준다.
with open("example.txt", "r") as file:
content = file.read()
print(content) # with문 블록을 벗어나면 자동으로 file 객체가 닫히게 된다.
- 관련 모듈
os모듈은 운영체제와 상호작용하기 위한 모듈인데 해당 모듈로 파일과 디렉토리를 다룰 수 있다. os.path 모듈은 파일 경로를 다루게 해주는데, 예를들어 os.path.exists("이름")은 파일이나 디렉토리의 존재여부를 확인할 수 있고, os.path.isfile("이름") 이나 os.path.isdir("이름")은 각각 파일이나 디렉토리 여부를 알려주며, os.mkdir("이름")은 해당 이름의 폴더를 만들어 준다.
shutil 모듈은 사용예시를 모아보았다.
import shutil
shutil.copy("source.txt", "destination.txt") # 파일 복사 : source를 destination으로
shutil.copytree("source_directory", "destination_directory") # 디렉토리 복사
shutil.move("source.txt", "destination.txt") # 파일 이동 또는 이름변경
shutil.rmtree("directory_to_delete") # 디렉토리 삭제
shutil.make_archive("archive", "zip", "directory_to_compress") # 디렉토리 압축
shutil.unpack_archive("archive.zip", "destination_directory") # 압축해제
pathlib모듈은 path를 객체로 다루는 모듈인데, 파일 경로를 결합하는 등에 사용할 수 있다.
pickle 모듈은 객체를 영속화 하는 경우에 사용한다. 즉, 파이썬 객체를 파일에 저장하거나 전송할 수 있게 한다.
import pickle
# 저장할 객체
data = {"name": "Alice", "age": 25, "city": "Seoul"}
# 객체를 파일에 저장
with open("data.pickle", "wb") as file:
pickle.dump(data, file)
# 파일에서 객체 불러오기
with open("data.pickle", "rb") as file:
loaded_data = pickle.load(file)
# 불러온 객체 출력
print(loaded_data)여기서 wb와 rb는 파일을 바이너리 모드로 열때 사용되는 파일모드이다. 참고로 파일은 바이너리파일과 텍스트파일이 있는데 컴퓨터가 이해할 수 있는 파일은 바이너리 파일이다.
3) Logging Handling
프로그램 실행동안 일어나는 정보를 기록으로 남겨야 할 경우가 있다. 파이썬에는 로그 관리 모듈로 logging 모듈이 있다. logging 모듈에서는 debug, info, warning, error, critical 함수가 제공된다.

import logging
# 로깅 설정
logging.basicConfig(
filename='app.log', # 로그 파일 경로
level=logging.INFO, # 로그 레벨 설정
format='%(asctime)s - %(levelname)s - %(message)s' # 로그 출력 형식
)
# 로그 출력
logging.debug('이 메시지는 디버그용입니다.')
logging.info('정보를 기록하는 메시지입니다.')
logging.warning('경고 메시지입니다.')
logging.error('에러가 발생했습니다.')
logging.critical('심각한 문제가 발생했습니다.')
logging 관련한 모듈로 설정파일을 다루는 configparser 모듈과 명령행 인자를 처리하는 모듈인 argparser 모듈이 있다.
4) Data Handling - CSV , HTML, XML, JSON
- CSV (Comma Separate Values)
이름에서부터 알 수 있듯이 쉼표로 구분한 텍스트 파일을 말한다. 엑셀 형식의 데이터를 프로그램에 상관없이 쓰기 위한 데이터 형식으로 이해하면 좋다고 한다. 엑셀 형식의 데이터기 때문에 당연히 엑셀로도 CSV 파일을 만들 수 있는데, 저장할 때 CSV 형식으로 저장하면 된다. 쉼표 외에도 탭으로 구분하는 TSV, 빈칸으로 구분하는 SSV 등이 있고 이들을 통칭하여 CSV (Character Separated Calues)라고 부른다.
파이썬은 CSV 파일 처리를 위한 csv 객체를 제공하고 있다. 구체적인 사용법은 예시를 통해 확인해 보자.
import csv
# CSV 파일 열기
with open('data.csv', 'r', encoding='utf-8') as file:
# CSV 파일 읽기
reader = csv.reader(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_MINIMAL)
# 각 행 출력하기
for row in reader:
print(row)
delimiter 매개변수는 필드를 구분하는 구분자를 설정하는데, 기본값은 쉼표(,)이다. quotechar 매개변수는 필드 값을 둘러싸는 따옴표(quote character)를 설정하고, 기본값은 큰따옴표(")이다. quoting 매개변수는 필드 값을 어떻게 인용할지 설정한다. 위 예시에서 나온 csv.QUOTE_MINIMAL은 필요한 경우에만 인용 부호를 사용하도록 지정하는 옵션이다.
- HTML (Hyper Text Markup Language)
HTML은 가장 널리 사용되는 마크업 언어이다. 일단 마크업과 마크다운의 개념에 대해 알고가자. 마크업과 마크다운은 모두 문서 작성을 위한 언어로 사용되지만, 목적과 문법적 특징에서 차이가 존재한다. 마크업은 태그(<요소명> 요소 <\요소명>)를 사용하여 요소를 정의하고, 각 요소에 속성을 부여하여 문서의 구조와 서식을 지정한다. 반면 마크다운은 간단하고 가독성 좋은 문서를 작성하기 위한 경량 마크업 언어이다.
웹에는 엄청나게 많은 정보가 있기 때문에 웹데이터를 다운받아 분석할 경우가 많다. HTML도 프로그램의 일종으로 볼 수 있어서 페이지마다 어쩐 규칙이 존재하는데, 이를 잘 분석하면 데이터의 추출이 가능해 진다.
HTML에서는 특정 패턴을 찾거나 조작하는 경우에 정규식(Regulation Expression)을 활용할 수 있다. 일단 비주얼 스튜디오 코드에서 정규식 검색 하는 경우 ctrl + H 후 눈꽃모양의 버튼을 눌러서 검색하면 된다는 점을 기억하자. 정규식에는 매우 방대한 문법이 있기 때문에, 기본적인 것 외에는 필요시 찾아서 검색하여 찾아보도록 하자.
번호문법설명예시
| # | 문법 | 설명 | 예시 |
| 1 | . | 어떤 문자 하나와 일치 | a.b는 "aab", "acb", "adb"와 일치 |
| 2 | * | 앞의 패턴이 0번 이상 반복되는 문자열과 일치 | ca*t는 "ct", "cat", "caat", "caaat"와 일치 |
| 3 | + | 앞의 패턴이 1번 이상 반복되는 문자열과 일치 | ca+t는 "cat", "caat", "caaat"와 일치 |
| 4 | ? | 앞의 패턴이 0번 또는 1번 나타나는 문자열과 일치 | colou?r는 "color"와 "colour"에 모두 일치 |
| 5 | [] | 대괄호 안에 포함된 문자 중 하나와 일치 | [aeiou]는 소문자 모음 중 하나와 일치 |
| 6 | () | 괄호 안에 포함된 패턴을 하나의 그룹으로 묶음 | (abc)+는 "abc", "abcabc", "abcabcabc"와 일치 |
| 7 | {} | 중괄호 안에 숫자나 숫자범위를 지정해 반복 횟수를 나타냄 | a{3}는 "aaa"와 일치 a{2,4}는 "aa", "aaa", "aaaa"와 일치 |
| 8 | \d,\w, \s |
숫자(digit), 단어(word), 공백(space)과 일치 | \d+는 하나 이상의 숫자로 이루어진 문자열과 일치 |
| 9 | \w | 와 일치합니다. | \w+는 하나 이상의 단어로 이루어진 문자열과 일치 |
| 9 | ^, $ | 각각 문자열의 시작과 끝을 나타냄 | ^Hello는 "Hello, World!"에서 일치하지만 "Hi, Hello"에서는 불일치 |
정규식 연습은 regexr.com을 활용하도록 하자.
파이썬에서 정규식은 re 모듈을 import하여 사용할 수 있다. 예시를 통해 살펴보자.
import re
# findall 예시: 정규식에 매치되는 모든 부분 문자열을 찾아 리스트로 반환
text = "apple, banana, cherry"
matches = re.findall(r"\b\w+\b", text)
print(matches) # ['apple', 'banana', 'cherry']
# search 예시: 정규식에 매치되는 첫 번째 부분 문자열을 찾아 반환
text = "The cat is on the mat"
match = re.search(r"\b\w{3}\b", text)
if match:
print(match.group()) # cat위 예시 하나만 해설해보면, \b는 단어 경계(단어와, 특수문자나 공백같은 비단어 사이의 위치를 말함)를 나타내는 메타문자이고 \w는 단어를 나타내는 메타문자이다. 즉 단어 경계로 둘러쌓인 한글자 이상의 단어문자를 나타내게 된다. "@hello"나 "two words"는 위 matches에 포함되지 않는다.
- XML (eXtensible Markup Language)
XML은 데이터를 구조화하고 계층적으로 표현하기 위한 태그를 사용하는 마크업 언어로 HTML과 유사하다. 이러한 마크업 언어를 다루기 위한 여러 도구들이 개발되어 있는데, beatifulsoup이 가장 많이 쓰이는 HTML, XML parser (cf parsing: 파싱이란 기계어 번역 쯤으로 이해하면 된다)이다. conda 가상환경에서 lxml과 beautifulsoup을 설치하여 사용하게 된다. 다음 예시를 이해해보자.
import requests
from bs4 import BeautifulSoup
# 웹 페이지의 HTML을 가져옴
response = requests.get('http://example.com')
html = response.text
# BeautifulSoup 객체 생성
soup = BeautifulSoup(html, 'html.parser')
# 특정 요소 추출 (find)
title = soup.find('h1')
print(title.text) # h1 요소의 텍스트 출력
# 여러 요소 추출 (find_all)
links = soup.find_all('a')
for link in links:
print(link.get('href')) # a 요소의 href 속성 값 출력
# 속성 값 추출
link = soup.find('a')
print(link.get('href')) # a 요소의 href 속성 값 출력
# 텍스트 추출
paragraph = soup.find('p')
print(paragraph.text) # p 요소의 텍스트 추출
- JSON (JavaScript Object Notation)
JSON은 간결성으로 기계나 인간 모두 이해하기 편한 텍스트 형태로 구성되어 있어 널리 활용되고 있다. 파이썬의 딕셔너리 타입과 유사하기 때문에 Dict type과 상호호환되는 형태의 데이터 타입이다. 또한 XML을 간단하게 줄일 수 있다는 장점이 있어 XML 대체제로 널리 사용된다. 파이썬에서는 json모듈을 통해 파싱, 저장 가능하다.
import json
# JSON 문자열
json_data1 = '{"name": "John Doe", "age": 25, "city": "New York"}'
# JSON 파싱
data1 = json.loads(json_data1)
# 파싱된 데이터 출력
print(data1['name']) # "John Doe"
print(data1['age']) # 25
print(data1['city']) # "New York"
# 파이썬 객체
data2 = {
"name": "John Doe",
"age": 25,
"city": "New York"
}
# JSON 생성
json_data2 = json.dumps(data2)
# 생성된 JSON 문자열 출력
print(json_data2) # '{"name": "John Doe", "age": 25, "city": "New York"}'
(2) Numpy - ndarray, indexing & slicing, operation, comparison, Fancy index, data i/0
Numpy는 파이썬의 고성능 과학 계산용 패키지로, 행렬이나 벡터 등 array 연산의 표준으로 볼 수 있다. 일반 리스트에 비해 빠르고 효율적이고, 다만 numpy는 dynamic supporting을 지원하지 않기 때문에 일반 리스트와 달리 한가지 타입의 데이터만을 넣어 줄 수 있다.
1) ndarray
- array 생성
import numpy as np
arr1 = np.array([1, 2, 3, 4, 5]) # 1차원 배열 생성
print(arr1) # [1 2 3 4 5]
arr2 = np.array([1, 2.5, 3, 4.7, 5])
print(arr2.dtype) # float64
matrix = np.array([[1, 2, 3], [4, 5, 6]]) # 2차원 배열 생성
print(matrix)
# [[1 2 3]
# [4 5 6]]넘파이를 이용해 ndarray라는 리스트와 유사한 객체를 생성하게 된다. 데이터타입을 지정하여 생성할 수 도 있지만, 미지정시 넘파이에서 타입을 자동으로 추론한다. 상술한 바와 같이 한가지 데이터 타입만을 넣을 수 있는데, 예시의 arr2에서 처럼 혼용되어 있는 경우 범용적인 float 타입으로 생성된다.
넘파이 배열을 생성한 후 attribute을 확인할 수 있다. 다음 예시를 통해 사용법을 확인하자.
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
# dtype: 배열의 데이터 타입을 반환합니다.
print(arr.dtype) # int64
# shape: 배열의 차원 크기를 튜플로 반환합니다.
print(arr.shape) # (2, 3)
# ndim: 배열의 차원 수를 반환합니다.
print(arr.ndim) # 2
# size: 배열의 요소 개수를 반환합니다.
print(arr.size) # 6세번째 예시에서, 배열의 차원이란 배열이 갖는 독립적인 축의 개수를 의미한다. 배열의 Rank는 차원 수를 나타내는 개념으로, Rank 0 배열은 스칼라 (ex 7) , Rank 1 배열은 벡터 (ex [10,10]), Rank 2 배열은 matrix (ex [[10,10],[15,14]]), 3이상인 n에 대해 Rank n의 경우 n-텐서 라고 부른다. 헷갈리면 대괄호 쌍의 수가 rank가 된다고 일단 기억하자.
넘파이 배열을 생성하는 함수에는 여러가지가 있다.
우선 arange 함수로 생성할 수 도 있다. range함수와 유사하지만 1차원의 넘파이 배열을 반환한다는 특징이 있는데, 사용법은 arr = np.arange(start, stop, step) 이고, 1차원 배열을 반환하므로 reshape로 handling 해줄 수 있겠다.
또한 ones, zeros, empty 로 생성할 수 있다. 예를들어 ones는 np.ones(shape, dtype, order)로 사용하여 1로 가득찬 array를 생성한다.
유사한 느낌으로 ones_like, zeros_like, empty_like으로 기존 어레이와 동일한 shape의 1이나 0으로 가득차거나 비어있는 array를 생성할 수 있다.
identity는 단위행렬을 생성하는 함수로, np.identity(5) 는 5 by 5의 단위행렬을 생성한다. 비슷한 eye는 대각선이 1인 행렬을 만드는데, 그 대각선의 index를 지정해 줄 수 있다는 점에서 다르다. np.eye(3,4,k=1) 의 경우 3 by 4 행렬을 만드는데, 대각선 시작 index인 k가 1이므로 3 by 3의 단위행렬 왼쪽에 0으로 이루어진 한 열을 추가했다고 보면 된다. 참고로 대각행렬의 값을 추출하는 함수로 diag 함수가 있다는 것도 기억하자.
np.random 모듈을 통해 랜덤한 array 생성이 가능하다. 해당 모듈에는 다양한 함수가 있고 여러 상황의 랜덤한 어레이 생성을 가능케 한다. 구체적으로, 데이터 분포에 따른 sampling으로 array를 생성한다.
- handling shape
넘파이의 reshape은 동일한 size에서 array의 shape을 변경해 준다. 예를들어 (2,4)의 matrix shape을 (8,)의 벡터나 (2,2,2)의 3-텐서 등으로 변경할 수 있다. 이때 -1을 reshape 함수의 인자로 전달하면 차원의 크기를 자동으로 계산해 준다.
import numpy as np
arr = np.array([1, 2, 3, 4, 5, 6])
reshaped_arr = arr.reshape(2, -1) # 2행, 열은 자동으로 계산
print(reshaped_arr)
# [[1 2 3]
# [4 5 6]]
flatten은 다차원 array를 1차원 array로 변환해준다.
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
flattened_arr = arr.flatten()
print(flattened_arr) # [1 2 3 4 5 6]
2) indexing & slicing
- indexing
예를들어 이차원 array x = [[1,2],[3,4]] 에서 일반 리스트처럼 x[0][0] = 1로 접근할 수 있는데, 특이한 점은 x[0,0]의 표기로도 접근할 수 있다는 점이다.
- slicing
일반 리스트와 달리 행과 열을 각각 나눠서 slicing이 가능하다는 특징이 있다. 예시를 살펴보자.
import numpy as np
arr = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
# 첫 번째 행 선택
slice1 = arr[0]
print(slice1) # [1 2 3]
# 두 번째 열 선택
slice2 = arr[:, 1]
print(slice2) # [2 5 8]
# 첫 번째 행과 두 번째 열 교차 지점 선택
slice3 = arr[0, 1]
print(slice3) # 2
# 두 번째 행부터 마지막 행까지, 두 번째 열부터 마지막 열까지 선택
slice4 = arr[1:, 1:]
print(slice4)
# [[5 6]
# [8 9]]
뿐만아니라 step을 이용한 slicing도 가능한데, 예를들어 arr[::2,::3]은 2차원 배열 arr을 행은 2개마다 하나씩, 열은 3개마다 하나씩 슬라이싱 된다.
3) operation
- axis
operation function을 통한 계산에서는 기준이 되는 차원 축이 요구된다. shape이 (2,3,4)라고 할때, axis는 인덱스 처럼 순서대로 axis = 0, 1, 2 가 된다. 다음 사진을 보면 이해가 쉽다.
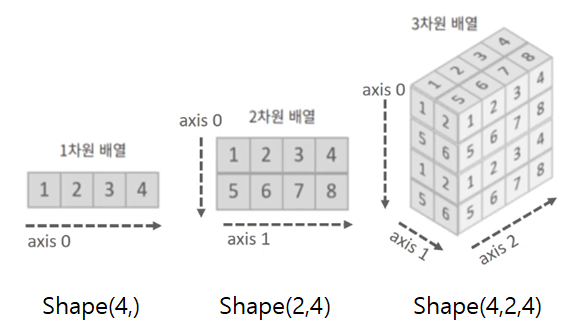
- operation functions
통계학에서 쓰는 mean, std, var 등 도 사용가능하고, sqrt, exp 등 다양한 수학 연산자를 제공하고 있다.
넘파이 array끼리 합쳐주는 함수도 기억해야 한다. vstack은 수직으로 붙여주고 hstack은 수평으로 붙여주는데, concatenate로 축을 지정하여 합칠수도 있다.
import numpy as np
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
arr3 = np.array([7, 8, 9])
# 배열을 수평으로 연결
result1 = np.concatenate((arr1, arr2, arr3))
print(result1) # [1 2 3 4 5 6 7 8 9]
arr4 = np.array([[1, 2, 3],
[4, 5, 6]])
arr5 = np.array([[7, 8, 9],
[10, 11, 12]])
# 배열을 수직으로 연결
result2 = np.concatenate((arr4, arr5), axis=0)
print(result2)
# [[ 1 2 3]
# [ 4 5 6]
# [ 7 8 9]
# [10 11 12]]
# 배열을 수평으로 연결
result3 = np.concatenate((arr4, arr5), axis=1)
print(result3)
# [[ 1 2 3 7 8 9]
# [ 4 5 6 10 11 12]]첫번째 예시처럼 axis를 지정하지 않으면 기본적으로 axis = 0 으로 지정된다.
- array operation
넘파이에서 기본적인 사칙연산을 지원하는데, array간 shape이 동일하면 같은 위치의 요소간 연산이 일어나게 된다. 이를 element-wise operations이라 한다. shape이 다른 배열의 경우에도 연산을 지원하는데 이를 broadcasting 연산이라 한다. 이는 뭔가 직관적인 연산이 아니므로 주의해야한다.
transpose로 전치행렬을 얻을 수 있다. x.transpose() 또는 x.T 등으로 사용한다.
matrix간 곱을 나타내는 방식으로는 dot, @, matmul 세가지가 있는데 각각 예시로 살펴보자.
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
# np.dot 함수를 사용한 행렬 곱
result1 = np.dot(a, b)
print(result1)
# [[19 22]
# [43 50]]
# @ 연산자를 사용한 행렬 곱
result2 = a @ b
print(result2)
# [[19 22]
# [43 50]]
# np.matmul 함수를 사용한 행렬 곱
result3 = np.matmul(a, b)
print(result3)
# [[19 22]
# [43 50]]
기타 timeit으로 주피터 환경에서 performance check가 가능하다는 점도 기억하자.
4) comparison
일반적인 대소비교와 비교할때 ndarray의 비교는 뭔가 특이한 맛이 있다. 예를들어 ndarr > 3에서는 각 요소마다 3과 비교하여 Boolean으로 이루어진 array를 반환한다. 참고로 일반 리스트 등은 오류가 뜰 것이다. np.all(ndarr<5), np.any(ndarr<5) 등은 모든 요소에 관하여 연산후 boolean을 반환한다. 비슷한 맥락에서 동일 shape의 배열간 비교의 경우 각 요소간 비교의 결과를 같은 shape의 boolean을 요소로 갖는 array를 반환한다.
logical_and (not, or 등) 도 유사한 느낌으로 기억하면 된다. np.logical_and(ndarr > 0 , ndarr <3) 이 어떤 의미이고 무엇을 반환할지 충분히 예상할 수 있다. 마찬가지로 isnan, isfinite은 각각 number가 아닌 것, finite number인 것에 대해 boolean의 배열을 반환한다.
이러한 comparison operation 함수들을 활용하여 조건에 대해 true인 index를 얻어 그 element만을 추출 할 수 있는데 이를 boolean index라 한다. 예를들어 ndarr = np.array([1,10,3,6,9])에서 ndarr > 5 는 array([False,True,False,True,True])가 되고, 이를 활용해 ndarr[ndarr > 5]로 array([10,6,9])를 얻을 수 있다.
np.where 함수는 조건에 따라 배열의 요소를 선택하는 기능을 수행한다.
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
# 배열에서 조건을 만족하는 요소 선택
result1 = np.where(arr > 2)
print(result1) # (array([2, 3, 4]),)
# 배열에서 조건을 만족하는 요소 대체
result2 = np.where(arr > 2, 10, arr) # arr에서 2보다 큰요소 찾음/ 조건만족시 10으로 대체/
print(result2) # [ 1 2 10 10 10]두번째 예시에서 파라미터 10을 다른 array로 쓸수도 있고, 파라미터 arr을 다른 array로 쓸 수 도 있다. 파라미터 arr은 원래 array인 arr를 썼으므로 조건 불만족시 그대로 유지하겠다는 의미이다.
argmax와 argmin은 각각 array의 최대값 또는 최소값의 index를 반환한다. axis를 지정하면 axis를 기반으로 한 최대값들 또는 최소값들을 반환한다.
5) fancy index
일반적인 index는 정수이지만 넘파이에서는 index 값으로 array를 사용할 수 있다. 다만 해당 array는 반드시 int 형태로 선언해야 하고 요소들은 범위를 넘지 않아야 한다. arr1[arr2] 나 arr1.take(arr2) 등으로 사용하면 된다. arr1이 matrix라면 arr1[arr2,arr3] 등도 가능하다.
6) data i/o
loadtxt와 savetxt 로 파일을 호출하고 저장할 수 있다.
(3) Pandas - DataFrame & Series, 데이터 생성 및 다루기, selection과 indexing, 내장함수, Groupby, Persistence
파이썬 라이브러리인 pandas는 구조화된 데이터의 처리를 지원하는데, 강의에서는 파이썬계의 엑셀이라고도 표현되었다. pandas는 DataFrame이라는 행과 열로 구성된 자료구조를 제공하여 엑셀 스프레드시트와 유사한 형태로 데이터를 다룰 수 있게 한다.
1) DataFrame, Series
DataFrame은 pandas에서 다루는 테이블 형태의 자료구조이다. 데이터프레임의 각 부분 호칭을 알아보자.

전체 데이터를 보통 Data table 또는 sample이라고 부른다. 찾아보니 용어정리가 의외로 어지러운데, 행제목을 index, 열제목을 header라 하는것 같다. 데이터프레임 자료에서 하나의 열 자료형을 series라고 한다. 즉 데이터프레임은 시리즈 들로 구성되어 있다.
Series는 column vector를 표현하는 객체로, pandas가 제공하는 자료구조중 하나이다. 예를들어 mylist = [1,2,3,4,5]에 대하여 my_obj = Series(data = mylist) 를 통해 시리즈 타입으로 변환할 수 있다. 시리즈 타입의 경우 indexing을 숫자 뿐 아니라 문자 등으로도 할 수 있는데, 이 경우 인덱싱이 딕셔너리와 유사해진다. 예를들어 my_obj = Series(data = mylist, index = myname)로 myname의 요소를 index이름으로 지정하는 것이다. 아무것도 안하면 리스트 인덱스처럼 0,1,2,3,4.. 의 인덱스를 갖게된다. 기억할 것은 index 값을 기준으로 시리즈(데이터프레임도 마찬가지)를 생성한다는 점이다. 즉 인덱스값이 많거나 적어도 그에 맞춰 생성된다.
2) 데이터 생성 또는 로딩, 다루기
- 데이터 생성, 로딩
데이터프레임은 다양한 방법으로 생성하는데, 가장 기본은 딕셔너리를 사용하여 생성하는 방법이다.
import pandas as pd
data = {'이름': ['철수', '영희', '민수'],
'나이': [25, 30, 35],
'성별': ['남', '여', '남']}
df = pd.DataFrame(data)
print(df)
생성할때 cloumn을 선택하여 생성할 수 도 있다. 예를들어, 위 예시에서 df2 = pd.DataFrame(data, columns = ['이름', '나이']) 로 했다면 이름과 나이 열만으로 생성된다. 비슷하게 df3 = pd.DataFrame(data, columns = ['이름', '나이', '성별', '소속']) 에서는 원래 데이터에 없던 '소속'열이 추가로 생성된다. 이 경우 데이터가 없으므로 NaN으로 채워질 것이다.
이런 식으로도 가능하다. df.어른 = df.나이 > 20 코드를 실행하면 어른 열이 추가되고 True로 채워지게 된다.
column 삭제 방법으로 del df[성별] 또는 df.drop("성별", axis =1) 등이 가능한데, 후자는 원래 df에는 변화가 없다.
실제 사용할때는 데이터를 어떤 url에서 가져오는 경우가 많다. 데이터 로딩하는 예시코드를 살펴보자.
import pandas as pd
my_url = 'http://example.com/data.csv' # 웹상의 CSV 파일 URL
df = pd.read_csv(my_url, sep = '\s+', header = None) # sep은 데이터 구분 기준 (\s+는 정규식으로 연속빈칸) / header 미지정
print(df.head(10)) # head()는 데이터 호출할때 가져올 양을 결정하는데, 아무것도 안적으면 5개를 가져온다. 예시는 10줄read_csv 함수는 url(파일도 가능하다)에서 CSV파일을 가져와 데이터프레임으로 변환한다. 다만 이 함수는 웹상의 CSV 데이터를 가져와 메모리에 저장하므로 대용량 데이터는 유의할 필요가 있다.
엑셀파일을 가져오려면 xlrd 모듈을 설치해줘야 한다. df = pd.read_excel("파일경로")로 불러올 수 있다.
이외에 열제목을 지정해주는 함수로 columns, numpy 타입으로 데이터를 나타내는 values 함수나 인덱스 리스트를 나타내는 index함수, 기타 name 함수도 기억하자.
- handling
dataframe은 series를 통해 다룰 수 있다는 느낌이 있다. 따라서 series를 생성하거나 다루는 여러 방법을 익힐 필요가 있는데, 일단 lambda나 map을 활용한 방법이 가능하다.
from pandas import *
s1 = Series([1,2,3,4,5])
print(s1.map(lambda x: x**2))
change = {1:1,2:4,3:9,4:16,5:25}
print(s1.map(change))
print(s1.replace(change))
# 0 1
# 1 4
# 2 9
# 3 16
# 4 25
# s1 자체는 그대로이다 : 변화시키려면 s1.replace(change,inplace=True)
dataframe의 특정 열이나 행에 어떤 함수나 lambda함수, 기타 직접 정의한 함수 등을 적용하려면 apply함수를 활용하면 된다. map함수는 series 객체에만 적용될 수 있다는 것과 비교해서 기억해두자.
import pandas as pd
# 데이터프레임 생성
df = pd.DataFrame({
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]
})
# 'A' 열의 각 원소에 대해 제곱하는 람다 함수 적용
df['A'] = df['A'].apply(lambda x: x**2)
데이터프레임이나 시리즈의 구조를 변경하는 여러 메서드가 존재한다.
unstack() 메서드는 멀티인덱스의 시리즈나 데이터프레임에서 특정 레벨의 인덱스를 열로 이동시킨다. 파라미터를 입력하지 않으면 기본적으로 가장 안쪽 레벨의 인덱스가 이동한다. 특정 레벨을 정하고 싶으면 unstack(level=0) 등으로 입력해주면 된다.
index = pd.MultiIndex.from_tuples([('one', 'a'), ('one', 'b'), ('two', 'a'), ('two', 'b')])
s = pd.Series(np.arange(1.0, 5.0), index=index)
print(s)
# one a 1.0
# b 2.0
# two a 3.0
# b 4.0
# dtype: float64
print(s.unstack())
# a b
# one 1.0 2.0
# two 3.0 4.0
stack() 메서드는 특정 레벨의 열 이름을 멀티 인덱스의 가장 안쪽 레벨로 이동시킨다.
reset_index()는 데이터프레임의 인덱스를 정수 인덱스로 초기화하고, 기존 인덱스는 열로 이동시킨다.
swaplevel()은 두 레벨의 인덱스를 서로 바꾼다.
sort_index()는 인덱스를 기준으로 데이터를 정렬하는데, level 매개변수를 통해 기준을 정할 수 있다.
- merge와 concat
판다스의 merge와 concat함수는 모두 데이터프레임이나 시리즈를 결합하는데 사용하는데, 사용 방법과 결과는 다르다.
merge함수는 두 데이터프레임을 공통 열이나 인덱스를 기준으로 합칠 때 사용하는데, inner join(두 df에 모두 존재하는 키만을 기준으로 합침), outer join(둘중 하나만 존재하면 합침, 없는 쪽은 NaN), left join, right join 등을 수행할 수 있다. 조인의 종류는 merge 함수의 how 매개변수를 통해 설정할 수 있고, 미지정시 기본값은 inner이다.
사용예시 : pd.merge(df1, df2, on='key', how='outer')
concat함수는 두 데이터프레임이나 시리즈를 축을 따라 그대로 이어붙일때 사용한다. 기본적으로는 행방향(위아래)으로 결합하지만 열방향(옆)으로 결합할 수 도 있다.
사용예시 : concatenated = pd.concat([df1, df2], axis=1) / 기본값은 axis = 0의 행방향이다.
3) selection & drop, 인덱싱
데이터프레임에서 시리즈로 접근하려면 column을 선택해야 하는데, 두 가지 방식이 있다. 위 예시에서는 df.이름 이나, df['이름']으로 이름 시리즈 추출이 가능하다.
데이터프레임의 인덱싱 방법으로는 loc과 iloc이 있다. loc은 index 이름, iloc은 index number임을 기억해야 한다.
import pandas as pd
# 예시 데이터프레임 생성
data = {'이름': ['철수', '영희', '민수'],
'나이': [25, 30, 35],
'성별': ['남', '여', '남']}
df = pd.DataFrame(data, index=['A', 'B', 'C'])
#### loc 예시
# 라벨을 사용하여 행 선택
print(df.loc['A'])
# 출력: 이름 철수
# 나이 25
# 성별 남
# Name: A, dtype: object
# 라벨을 사용하여 열 선택
print(df.loc[:, '나이'])
# 출력: A 25
# B 30
# C 35
# Name: 나이, dtype: int64
# 라벨을 사용하여 특정 행과 열 선택
print(df.loc['B', '이름'])
# 출력: 영희
#### iloc 예시
# 정수 인덱스를 사용하여 행 선택
print(df.iloc[0])
# 출력: 이름 철수
# 나이 25
# 성별 남
# Name: A, dtype: object
# 정수 인덱스를 사용하여 열 선택
print(df.iloc[:, 1])
# 출력: A 25
# B 30
# C 35
# Name: 나이, dtype: int64
# 정수 인덱스를 사용하여 특정 행과 열 선택
print(df.iloc[1, 0])
# 출력: 영희
4) pandas 내장함수 정리
- unique(): 시리즈 데이터의 유일한 값을 리스트로 반환합니다.
- head(), tail(): 데이터프레임의 처음 또는 마지막 몇 개의 행을 반환합니다.
- describe(): 데이터프레임의 숫자형 열에 대한 기초 통계량을 반환합니다.
- mean(): 데이터프레임의 숫자형 열의 평균 값을 계산합니다.
- max, nim(): 데이터프레임의 각 열에서 최대 값 또는 최소 값을 찾습니다.
- isnull(): 데이터프레임의 행 또는 열에서 Nan 값의 index를 반환합니다.
- drop(): 데이터프레임에서 특정 행이나 열을 삭제합니다.
- sort_values() : 열 값을 기준으로 데이터를 정렬합니다.
- pd.options.display.max_rows = 100 : 보이는 행 수를 100개로 조정
5) Groupby
- Groupby
groupby는 데이터를 그룹화하여 그룹별로 연산을 수행하기 위한 함수이다. 특정 열을 기준으로 데이터를 그룹화하여, sum, mean, max, min 등 다양한 함수를 적용하여 그룹별 계산을 수행할 수 있게 한다.
import pandas as pd
data = {
'Company': ['GOOG', 'GOOG', 'MSFT', 'MSFT', 'FB', 'FB'],
'Person': ['Sam', 'Charlie', 'Amy', 'Vanessa', 'Carl', 'Sarah'],
'Sales': [200, 120, 340, 124, 243, 350]
}
df = pd.DataFrame(data)
print(df.groupby('Company').sum())
# Person Sales
# Company
# FB CarlSarah 593
# GOOG SamCharlie 320
# MSFT AmyVanessa 464
pivot_table, crosstab은 groupby와 같이 데이터를 집계하거나 재구조화하는데 사용되는 메서드 들이다. pivot_table은 groupby와 비슷한 집계연산을 수행하지만 결과를 2차원 테이블 형태로 제공하여 더욱 직관적인 분석을 가능하게 한다. corsstab은 두 열의 교차빈도, 비율, 덧셈등을 계산하여 테이블 형태의 결과를 제공하는데, 두 변수간의 관계를 요약하는데 유용한 메서드로 범주형 데이터를 다룰때 자주 사용된다.
- grouped data handling
group화 된 상태에서는 각 그룹을 for문을 통해 순회하며 데이터를 추출할 수 있다. 이 경우 각 그룹은 그룹 이름과 그룹 데이터를 포함하는 튜플로 반환하게 된다.
grouped = df.groupby('Company')
for name, group in grouped:
print(f"Company: {name}")
print(group)
print("\n")
판다스의 get_group 메서드로 groupby로 생성된 그룹 중에서 특정 key값을 가진 그룹의 데이터를 직접 추출할 수 있다. 위 예시에 이어서, print(grouped.get_group("GOOG"))를 실행하면 회사명이 GOOG인 행들만을 포함하는 데이터 프레임이 출력된다.
그룹화된 데이터에 대해 다양한 연산을 수행할 수 있도록 도와주는 agg, transform, filter 함수를 알아보자. agg는 그룹별 다른 연산을 동시에 수행하고 싶을때 사용하는데, 개인적으로 적용하려는 연산을 문자열의 형태로 전달한다는 점이 특이했다. transform은 그룹별로 같은 연산을 수행할 때 사용하고, 원본 데이터프레임과 같은 크기의 결과를 반환한다. filter는 그룹별로 특정 조건을 만족하는 데이터만을 추출해준다.
import pandas as pd
data = {
'Company': ['GOOG', 'GOOG', 'MSFT', 'MSFT', 'FB', 'FB'],
'Person': ['Sam', 'Charlie', 'Amy', 'Vanessa', 'Carl', 'Sarah'],
'Sales': [200, 120, 340, 124, 243, 350]
}
df = pd.DataFrame(data)
grouped = df.groupby('Company')
print(grouped.agg({'Sales': ['sum', 'mean', 'max']})) # Sales에 대해 sum, mean, max를 모두 계산
# Sales
# sum mean max
# Company
# FB 593 296.5 350
# GOOG 320 160.0 200
# MSFT 464 232.0 340
print(grouped['Sales'].transform(lambda x: x - x.mean())) # 각 그룹의 평균을 뺀 값 계산
# 0 40.0
# 1 -40.0
# 2 108.0
# 3 -108.0
# 4 -53.5
# 5 53.5
# Name: Sales, dtype: float64
print(grouped.filter(lambda x: x['Sales'].sum() > 300)) # Sales의 합계가 300을 초과하는 그룹만 남김
# Company Person Sales
# 0 GOOG Sam 200
# 1 GOOG Charlie 120
# 2 MSFT Amy 340
# 3 MSFT Vanessa 124
# 4 FB Carl 243
# 5 FB Sarah 350
6) persistence
판다스는 데이터를 파일로 저장하고 로드하는 여러가지 방법을 지원하여 데이터를 영속적으로 저장하고 재사용할 수 있는데, 이러한 과정을 데이터의 persistence라고 한다. 데이터 로딩시 db connection 기능을 제공하는데, squlite3를 import하여 하는 database 연결코드를 참고하도록 하자. 엑셀 파일과 관련해서도 가능한데, openpyxl이나 XlsxWriter의 install이 필요하다.
3. 느낀점
파이썬 정리가 굉장히 오래걸렸는데, 상세한 정리보다는 직접 써보면서 익히는게 맞다는 것을 느꼈다. 파이썬 내용은 정리하기엔 너무 잡다한 문법이나 그런게 많은데, 이런 것들은 그때그떄 필요할때 찾아 쓰는게 맞을 것이다. 다만 그러한게 있는지 정도는 기억하면 좋겠다. 결국 너무 상세하게 정리할 필요까지는 없는 것 같은데, 이게 또 정리하다 보면 그 경계를 확실히 하는게 어렵다. 결국 모든 불의타를 정리해버린게 아닌가 싶은데, 그래도 ai math 부분은 정리가 수월하리라 기대중이다.
그리고 시급한 과제가 에디터나 터미널 같은 프로그램 사용법을 익히는 것이다. 그나마 코테 준비할때 많이써본 파이참 외에는 아직도 미숙하다. 가상환경 설정같은 부분이 강의를 따라하면 문제가 없지만 혼자 스스로 만들려 할때는 의외로 잘 안된다. 시간이 해결해 주겠지만, 가급적 그 시간을 줄여 빠르게 적응하고 싶다.
'공부 > Deep Learning : 네부캠 AI Tech' 카테고리의 다른 글
| 부스트캠프 1주차 #5 - 확률론, 통계학 (0) | 2023.11.12 |
|---|---|
| 부스트캠프 1주차 #4 - 벡터와 행렬, 경사하강법, 신경망 (0) | 2023.11.11 |
| 부스트캠프 1주차 #2 - 파이썬 문법, 클래스, 모듈과 패키지 (1) | 2023.11.08 |
| 부스트캠프 1주차 #1 - OS, 터미널, 개발환경 (0) | 2023.11.07 |
| 네이버 부스트캠프 AI tech 6기 합격후기 (1) | 2023.10.22 |



